
java基础复习
本文根据作者对java基础的掌握程度而写,只记录了我自己容易遗忘的点,可能并不适合java新手学习😵💫
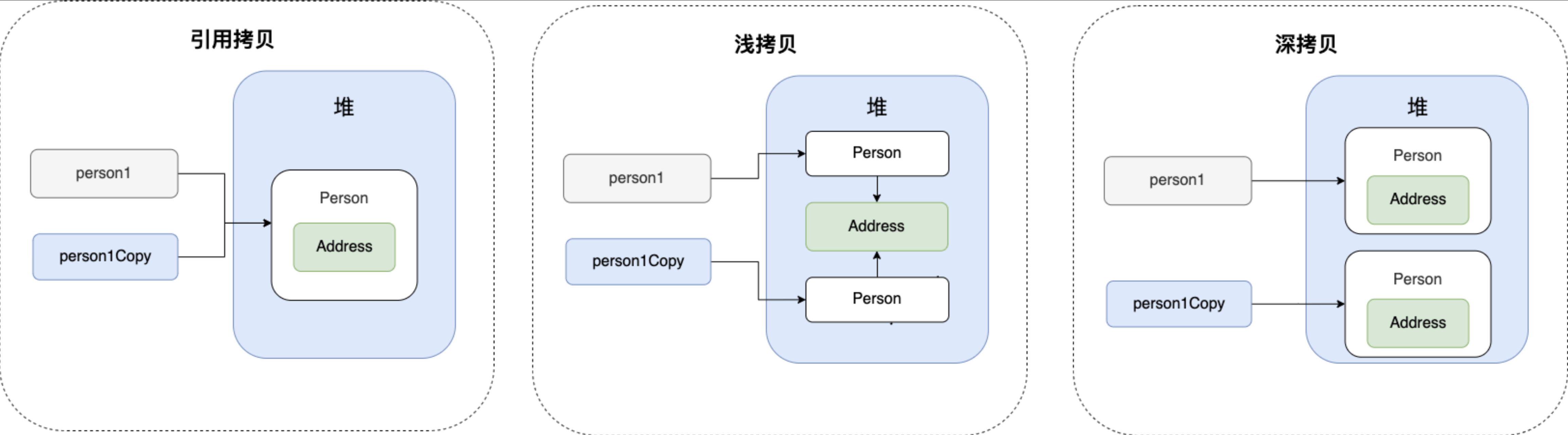
1.深拷贝、浅拷贝以及引用拷贝:
2.Object类中的常见方法:
1 | /** |
3.hashCode() 和 equals()
Java hashCode() 和 equals()的若干问题解答
4.字符串相关
String:不可变
原因是 String底层使用private、final修饰一个char[],而且并不把修改该char[]的方法暴露,因此不可变
java9之后,String使用 byte[] 存储内容 ——原因是:
- byte的存储空间为1B;char为2B
- 大多数情况下 1B的空间能表示我们使用的字符—-使用Latin-1编码方式
- 当我们使用到一些特殊字符时,才会用2个byte存储一个字符(此时存储效率与使用char一样)
字符串拼接:
Java 语言本身并不支持运算符重载,“+”和“+=”是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
🌟String 对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
🌟不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。
字符串常量池的作用了解吗?
JDK1.7后,字符串常量池在堆中
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
🍓字符串常量池保存的是:字符串(key)和 字符串对象的引用(value)的映射关系(维护了一个HashMap),字符串对象的引用指向堆中的字符串对象。
因此如果在常量池中找不到某字符串,会在堆中创建以该字符串生成的String对象,再将其地址存储到常量池HashMap的Value中!
至此,常量池中增加了一个字符串常量。
因此面对问题:String s1 = new String(“abc”);创建了几个String对象?
—1.为s1创建一个空的String对象,
- 如果常量池中没有“abc”,那么首先还需要在堆中创建一个存储了“abc”的String对象,将该对象的引用存入常量池,再为 为s1创建的对象 赋值,因此创建了2个String对象
- 如果常量池中有“abc”,那么直接为 为s1创建的对象 赋值即可,只创建了一个对象。
intern 方法有什么作用?
String.intern() 是一个 native(本地)方法,其作用是**将指定的字符串对象的引用保存在字符串常量池中**,可以简单分为两种情况:
- 如果字符串常量池中保存了对应的字符串对象的引用,就直接返回该引用。
- 如果字符串常量池中没有保存了对应的字符串对象的引用,那就在常量池中创建一个指向该字符串对象的引用并返回。
1 | // 在堆中创建字符串对象”Java“ |
5.包装类型的缓存机制了解么?
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
⚠️包装类等值比较的注意点:
6.为什么浮点数运算的时候会有精度丢失的风险?
浮点数运算精度丢失代码演示:
float a = 2.0f - 1.9f; float b = 1.8f - 1.7f;
System.out.println(a); // 0.100000024
System.out.println(b); // 0.099999905
System.out.println(a == b); // false
为什么会出现这个问题呢?
这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么浮点数没有办法用二进制精确表示。
7.如何解决浮点数运算的精度丢失问题?
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
1 | BigDecimal a = new BigDecimal("1.0"); |
8.如何实现数组和 List 之间的转换?
- 数组转 List:使用 Arrays. asList(array) 进行转换。
- List 转数组:使用 List 自带的 toArray() 方法。
9.CAS原理
内存中:
- 待修改的值
线程持有:
- 预期值
- 新值
工作方式:线程想要修改内存中的一个值,那么该线程先**从内存中读取该值,作为预期值,在进行业务流程后生成新值**,在修改内存中值之前进行判断:
1.如果预期值 == 待修改的值,说明在此期间该‘值’未发生改变,线程便可以将内存中的旧值替换为新值。
2.如果预期值 != 待修改的值,说明在此期间值发生了改变,线程不能进行修改,常见的应对措施是:重新获取预期值和计算新值,再次进行判断。。
⚠️在*1.*中,在此期间该‘值’未发生改变的情况下 可能发生ABA问题,这种情况下本应重试,不允许修改,但是CAS却检测不出来
解决方案:添加一个序号(或 时间戳)
集合类
ArrayList源码学习
1 | // 序列化 ID |
ArrayList 中的elementData对象被transient修饰,原因是:
- transient修饰的变量不会被序列化,但是ArrayList底层在序列化时,会调用自己重新实现的
writeObject()和readObject()这两个方法来序列化数组元素,目的是防止ArrayList中开辟了空间但是没有被使用的空间也被序列化 - ArrayList底层重新实现的
writeObject()和readObject()中,序列化elementData时是读取了size然后一个一个进行序列化传输的。即:**ArrayList 重写了 JDK 序列化的逻辑,只把 elementData 数组中有效元素的部分序列化,而不会序列化整个数组。**
1 | /** |
ArrayList扩容机制:
ArrayList通过空构造方法时并不会创建默认大小的elementData,而是让elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA这个空数组,在添加元素时,ArrayList会先看看elementData是否为空数组,是的话就给他赋值为默认大小的数组,再使用ensureCapacityInternal(size + 1) 来判断现在elementData的大小是否能放入size + 1个元素,如果不行则扩容。
🌟ArrayList源码中有个参数叫做 modCount,它有什么用?
它很像乐观锁的版本检测的过程
modcount(modification count)是一种用于记录数据结构变化状态的计数器,通常用于在迭代器中实现快速失败(fail-fast)机制。
在一些数据结构(如ArrayList、HashMap等)中,当数据结构发生变化(如增删元素)时,会增加modcount的值。当迭代器开始遍历数据结构时,会将当前的modcount值保存下来。在每次迭代器执行操作时,会检查当前的modcount值是否与保存的值相等。如果不相等,就表示数据结构发生了变化,迭代器会立即抛出ConcurrentModificationException异常,实现了快速失败。
modcount的作用是在并发环境中,保证多个线程之间不会产生隐患的访问竞态条件。通过检查modcount值,可以检测到其他线程对数据结构的修改,从而及时发现并防止遍历过程中的异常情况发生。
需要注意的是,modcount并不提供线程安全性。在并发环境中操作modcount和数据结构仍然需要使用适当的同步机制来保证线程安全性。modcount的主要作用是实现快速失败机制,及时检测并发修改,而不是作为线程同步的方法。
ConcurrentHashMap:
JDK1.7:
1.Segment 段:
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个 ConcurrentHashMap 由一个个 Segment 组成, Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个segment。
2.线程安全(Segment 继承 ReentrantLock 加锁):
简单理解就是, ConcurrentHashMap 是一个 Segment 数组, Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
3.并行度(默认 16):
concurrencyLevel:并行级别、并发数、 Segment 数,默认是 16,
即 ConcurrentHashMap 有 16 个 Segments,所以理论上,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
🌟segment 数量在 ConcurrentHashMap 初始化后就不可改变
🌟每个 segment 中的hashmap大小可扩容,类似HashMap
线程写一个segment时,需要获取该segment代表的ReentrantLock,**读取数据并不需要获取锁**,因此只有多个线程同时在写一个segment时才会发生冲突,这时未抢到锁的线程将被阻塞!!!
JDK1.8:
由于JDK1.7中segment使用拉链法解决hash冲突,链表过长会导致性能下降。
JDK1.8中当链表长度>8时,会自动转换成红黑树存储
并且使用 CAS + synchronized 来保证并发的安全性,**只锁定当前链表或红黑二叉树的首节点**,只要节点 hash 不冲突,就不会产生并发,相比 JDK1.7 的 ConcurrentHashMap 效率又提升了 N 倍!
枚举类:
demo Code:
1 | public enum DemoEnum { |
其中:Red、Blue、Green被称为**枚举常量**
枚举常量可以对应有多个属性,如上述枚举类中的“color”,“desc”
⚠️:在外部类想要访问如DemoEnum.Red.color的话,由于color、desc都是private属性,我们需要在DemoEnum中自定义有关私有属性的访问方法。
- 枚举常量:RED、BLUE、GREEN 是枚举类 DemoEnum 的三个实例化对象,它们是唯一的、已命名的常量。( 而(“r”, “🌹”) 就是构造RED这个实例化对象的初始变量 )
- 构造方法:枚举类的构造方法默认是私有的,只能在枚举类内部使用。在这个示例中,使用私有构造方法来为每个枚举常量设置对应的颜色和原始值。
- values() 方法:这个示例在 main() 方法中使用 TestEnum.values() 方法获取 DemoEnum 枚举类中的所有枚举常量,并进行遍历输出。
- valueOf(String name) 方法:通过 TestEnum.valueOf(“RED”) 可以获取枚举常量名为 “RED” 的枚举对象。
- ordinal() 方法:枚举常量的 ordinal() 方法返回它们在枚举类型中定义的顺序值(下标,从0开始)。
- compareTo() 方法:通过 RED.compareTo(BLACK) 和 BLACK.compareTo(GREEN) 可以比较两个枚举常量的顺序,返回一个整数值。
优点:
易读性和可维护性:枚举类型中的常量是有意义的、自描述的,使得代码更易读、易理解和易于维护。枚举常量具有唯一的名称,提供了更好的文档和注释。
类型安全:枚举类型在编译时进行静态类型检查,这意味着编译器可以确保只使用有效的枚举常量,提供了更高的类型安全性。
可限定的值集合:枚举类型定义了一个有限的值集合,限定了有效的取值范围。这可以帮助避免程序中出现无效或意外的取值。
避免魔法数值:使用枚举类型可以避免使用硬编码的魔法数值,提供了更好的代码可读性和可维护性。
增强的编译器支持:枚举类型在编译器层面提供了一些额外的支持,如自动添加常用方法(如values()、valueOf())、枚举常量的顺序等。
适用于状态和选项的表示:枚举类型非常适用于表示状态、选项和固定集合,如季节、颜色、星期几等。
缺点:
不适用于动态变化的数据:枚举类型是在编译时定义的,其常量集合是固定的。如果需要表示动态变化的数据集合,枚举类型可能不适合。
不适用于大型数据集合:如果需要表示大型的数据集合,枚举类型的常量定义可能会变得冗长和繁琐。
缺乏扩展性:枚举类型的常量是在编译时确定的,不支持动态添加或删除常量。因此,如果需要频繁地修改常量集合,可能会导致代码的改动和维护成本的增加。
不支持继承:枚举类型不支持继承,无法实现枚举类型之间的继承关系。
异常分类及处理
4.1.1. 异常概念
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器。
4.1.2. 异常分类
Throwable 是 Java 语言中所有错误或异常的超类。下一层分为 Error 和 Exception
Error (非检查异常):
- Error 类是指 java 运行时系统的内部错误和资源耗尽错误。应用程序不会抛出该类对象。如果出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。
Exception( RuntimeException(非检查异常)、 CheckedException(检查异常) ):
Exception 又 有 两 个 分 支 , 运行时异常(非检查异常) RuntimeException , 检查异常CheckedException。
RuntimeException 如 : NullPointerException 、 ClassCastException ; RuntimeException 是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。 如果出现 RuntimeException,那么一定是程序员的错误。
- 比如除数为 0 错误 ArithmeticException,强制类型转换错误 ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等
CheckedException如 : I/O 错误导致的 IOException、 SQLException。一般是外部错误,这种异常都发生在编译阶段, **Java 编译器会强制程序去捕获此类异常,即会出现要求你把这段可能出现异常的程序进行 try catch**,该类异常一般包括几个方面:
- 试图在文件尾部读取数据
- 试图打开一个错误格式的 URL
- 试图根据给定的字符串查找 class 对象,而这个字符串表示的类并不存在
4.1.3.三种处理方式
- 在try-catch中自定义throw错误信息
- throws给上层
- 啥也不做,系统默认帮你抛异常
4.1.4. Throw 和 throws 的区别:
位置不同:
1. throws 用在方法上,后面跟的是<u>异常类,可以跟多个</u>; 而 throw 用在函数内,后面跟的是<u>异常对象</u>。
功能不同:
throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式; throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
🌟throws 表示出现异常的一种可能性,并不一定会发生这些异常; throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
4.1.5 try-cache-finally 与try-with-resources
try-finally 是java SE7之前我们处理一些需要关闭的资源的做法,无论是否出现异常都要对资源进行关闭。
如果try块和finally块中的方法都抛出异常那么try块中的异常会被抑制(suppress),只会抛出finally中的异常,而把try块的异常完全忽略。
这里如果我们用catch语句去获得try块的异常,也没有什么影响,catch块虽然能获取到try块的异常但是对函数运行结束抛出的异常并没有什么影响。
try-with-resources语句能够帮你自动调用资源的close()函数关闭资源不用到finally块。
前提是只有实现了Closeable接口的才能自动关闭
1 | public void clean(String path, Consumer<String> consumer) throws IOException { |
这是try-with-resources语句的结构,在try关键字后面的( )里new一些需要自动关闭的资源。
这个时候如果方法 readLine 和自动关闭资源的过程都抛出异常,那么:
- 函数执行结束之后抛出的是try块的异常,而try-with-resources语句关闭过程中的异常会被抑制,放在try块抛出的异常的一个数组里。(上面的非try-with-resources例子抛出的是finally的异常,而且try块的异常也不会放在fianlly抛出的异常的抑制数组里)
- 可以通过异常的
public final synchronized Throwable[] getSuppressed()方法获得一个被抑制异常的数组。 try块抛出的异常调用getSuppressed()方法获得一个被它抑制的异常的数组,其中就有关闭资源的过程产生的异常。
try-with-resources 语句能放多个资源,使用 ; 分割
最后任务执行完毕或者出现异常中断之后是根据new的反向顺序调用各资源的close()的。后new的先关。
反射
4.2.1.反射机制概念
在 Java 中的反射机制是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能成为 Java 语言的反射机制。
4.2.2. 反射的应用场合
🌟:
程序在运行时还可能接收到外部传入的对象, 该对象的编译时类型为 Object,但是程序有需要调用该对象的运行时类型的方法。为了解决这些问题, 程序需要在运行时发现对象和类的真实信息。然而,如果编译时根本无法预知该对象和类属于哪些类,程序只能依靠运行时信息来发现该对象和类的真实信息,此时就必须使用到反射了。
4.2.3. Java 反射
API反射 API 用来生成 JVM 中的类、接口或则对象的信息。
1. Class 类:反射的核心类,可以获取类的属性,方法等信息。
Field 类: Java.lang.reflec 包中的类, 表示类的成员变量,可以用来获取和设置类之中的属性值。
Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法。
4.2.4. 反射使用步骤(获取 Class 对象、调用对象方法)
获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法。
调用 Class 类中的方法,既就是反射的使用阶段。
使用反射 API 来操作这些信息。
具体使用看java基础
反射、注解、内部类、泛型、序列化等看javaguide吧
 wechat
wechat alipay
alipay



